
들어가며
머신러닝이라는 단어를 들으면 많은 사람들이 고양이와 개를 구분하는 이미지 인식 모델이나, 유창하게 대화를 이어가는 ChatGPT 같은 AI를 떠올린다. 하지만 실제 기업과 현장에서 가장 많이 쓰이는 데이터 형식은 따로 있다. 바로 테이블(Tabular) 데이터이다.
이 글에서는 테이블 데이터가 무엇인지, 왜 다루기 어려운지, 그리고 어떤 문제들을 풀 수 있는지를 비전공자도 이해할 수 있는 수준으로 설명한다.
Tabular 데이터란 무엇인가?
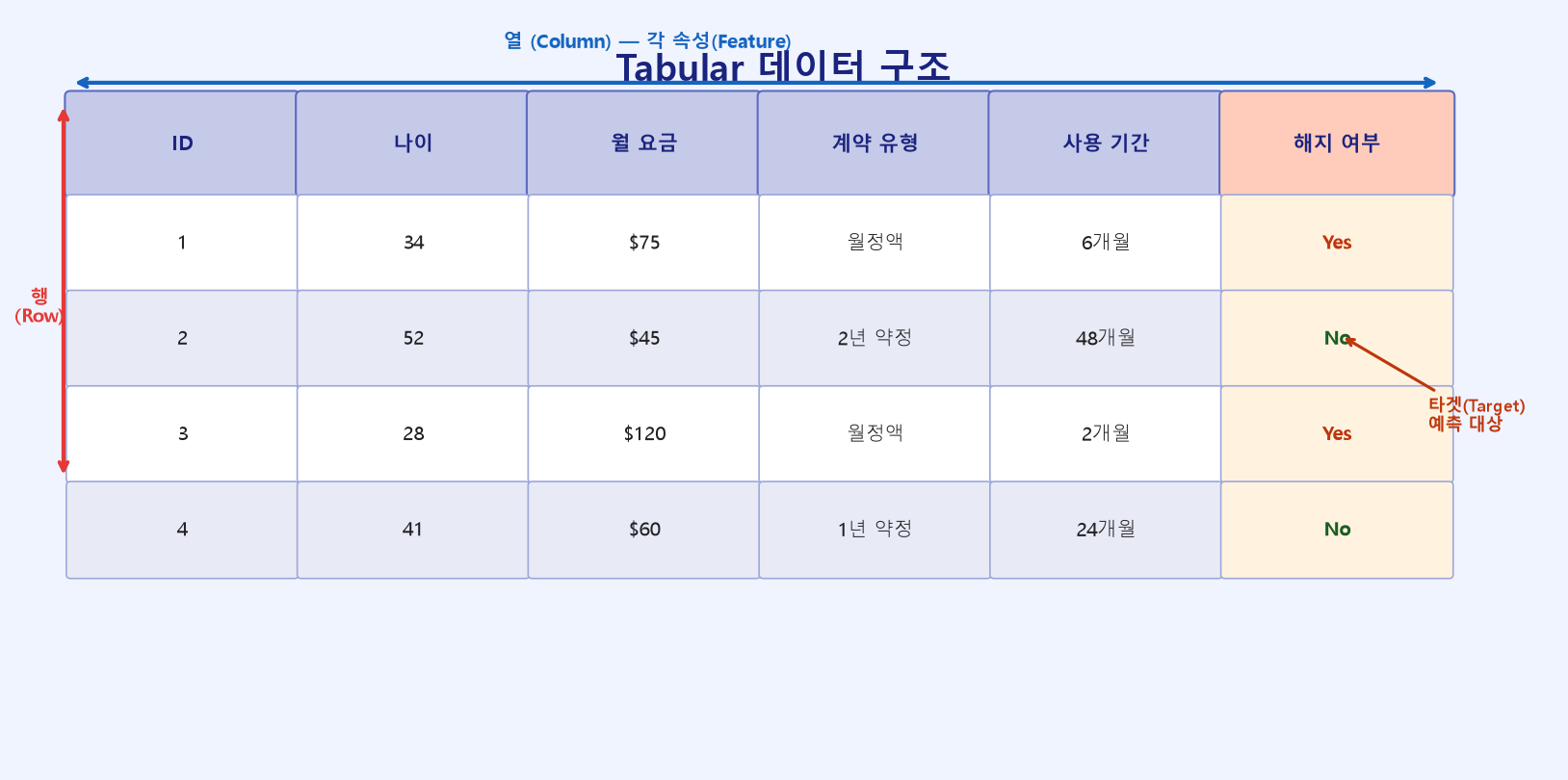
Tabular(테이블형) 데이터란, 이름 그대로 행(row)과 열(column)로 이루어진 표 형태의 데이터이다. 엑셀이나 구글 스프레드시트를 떠올리면 바로 이해된다.
- 행(Row): 하나의 관측값, 즉 데이터 한 건을 나타낸다.
예를 들어 고객 한 명, 거래 한 건, 환자 한 명이 각각 하나의 행이 된다. - 열(Column): 각 관측값이 가진 속성(feature)을 나타낸다.
예를 들어 나이, 요금, 계약 유형, 사용 기간 같은 정보들이다. - 타겟(Target): 예측하고 싶은 값이 담긴 특별한 열이다.
예를 들어 "고객이 서비스를 해지했는가(Yes/No)" 같은 것이다.
아래 예시 표를 보면 직관적으로 이해된다.
| ID | 나이 | 월 요금 | 계약 유형 | 사용 기간(월) | 해지 여부 |
|---|---|---|---|---|---|
| 1 | 34 | $75 | 월정액 | 6 | Yes |
| 2 | 52 | $45 | 2년 약정 | 48 | No |
| 3 | 28 | $120 | 월정액 | 2 | Yes |
| 4 | 41 | $60 | 1년 약정 | 24 | No |
이런 형식이 바로 Tabular 데이터이다. 우리가 일상에서 접하는 거의 모든 데이터베이스가 이 형식으로 저장된다.
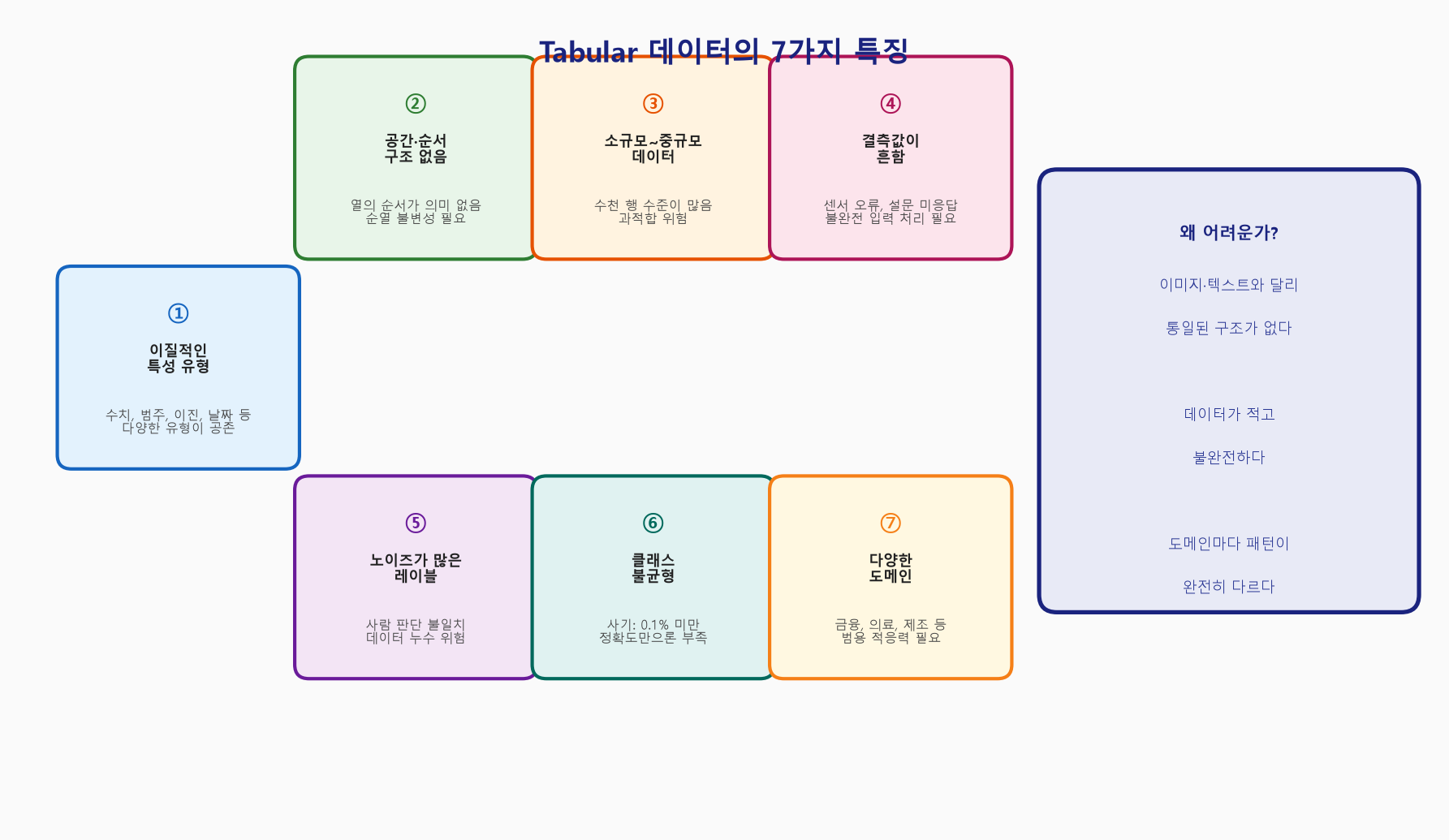
Tabular 데이터의 특징들 — 왜 이게 어렵나?
이미지나 텍스트 데이터를 다루는 딥러닝이 워낙 유명하다 보니,
Tabular 데이터는 "그냥 표니까 쉽겠지"라고 오해하기 쉽다. 하지만 실제로는 독특한 도전 과제들이 존재한다.
1. 열마다 데이터 종류가 다르다 (이질적인 특성)
이미지 데이터는 모든 픽셀이 0~255 사이의 숫자라는 동일한 형식을 갖는다.
하지만 Tabular 데이터는 하나의 행 안에 완전히 다른 종류의 정보가 섞여 있다.
| 데이터 유형 | 예시 |
|---|---|
| 수치형 (Numerical) | 나이, 가격, 온도, 자녀 수 |
| 범주형 (Categorical) | 국가, 색상, 카테고리, 학력 수준 |
| 이진형 (Binary) | Yes/No, True/False, 0/1 |
| 날짜/시간형 (Datetime) | 타임스탬프, 날짜 |
| 자유 텍스트 (Text) | 사용자 후기 |
| 기타 | 이미지, 동영상 |
모든 열이 서로 다른 통계적 성질을 갖기 때문에, 모델은 이 이질성을 모두 처리할 수 있어야 한다.
2. 열의 순서가 의미가 없다 (공간·순서 구조 없음)
이미지에서는 인접한 픽셀끼리 연관이 있다. 텍스트에서는 단어의 순서가 의미를 만든다. 그래서 이미지에는 CNN(합성곱 신경망)이, 텍스트에는 RNN이나 Transformer가 잘 맞는다.
반면 Tabular 데이터는 열의 순서에 특별한 의미가 없다. "나이" 열과 "연봉" 열의 순서를 바꾼다고 해서 데이터의 의미가 달라지지 않는다. 따라서 Tabular 데이터용 모델은 열의 순서에 관계없이 같은 결과를 내야 한다.
이를 순열 불변성(permutation invariance)이라고 한다.
3. 데이터 양이 적다 (소규모~중규모 데이터셋)
이미지나 텍스트용 딥러닝 모델은 수십억 개의 샘플로 학습된다. 하지만 현실의 Tabular 데이터셋은 고작 수천 행인 경우가 많고, 열의 수도 수십~수천 개에 불과하다.
데이터가 적으면:
- 복잡한 딥러닝 모델은 과적합(overfitting) 되기 쉽다 (학습 데이터에만 특화되고 새 데이터에는 못 씀)
- 오히려 귀납적 편향(inductive bias) 이 강한 모델, 즉 의사결정 트리 기반 앙상블 모델(XGBoost, LightGBM 등)이 더 잘 작동한다.
여기서 과적합(overfitting)를 비유하면,
- 훈련 데이터 = 기출문제 3개: 공부할 수 있는 문제가 3개밖에 없는상황
- 과적합 모델 = 암기 천재 학생: 학생은 머리가 너무 좋아서 문제의 개념을 이해하는 대신, 문제의 글자 크기, 점 하나, 오타까지 통째로 외워버린다.
- 테스트 결과 = 실전 시험 빵점: 기출문제 3개는 100점을 맞지만, 실전 시험에서 숫자나 단어가 조금만 바뀌어 나오면 아예 풀지 못한다. 보편적인 원리를 배운 게 아니라 특정 문제 자체를 외웠기 때문이다. 운용을 하지 못함.
즉, 경험한 표본이 너무 적은 상태에서 눈앞의 조건에만 완벽하게 맞추려다 보니 정작 중요한 본질(규칙)을 놓치는 현상으로
결국, 한 사람을 위한 요리사가 되는것이다.
4. 결측값이 흔하다 (Missing Values)
현실 데이터에는 빈칸이 정말 많다.
- 센서가 잠깐 꺼진 사이 값이 빠진다
- 설문 응답자가 일부 질문을 건너뛴다
- 여러 출처에서 데이터를 합쳤을 때 형식이 맞지 않는다
모델은 이런 불완전한 입력을 처리할 수 있어야 한다.
5. 레이블이 시끄럽고 불완전하다 (Noisy Labels)
예측 대상인 "정답(Label)"도 완벽하지 않다.
- 사람이 직접 붙인 레이블은 일관성이 없을 수 있다
- 회사 정책이 시간에 따라 바뀌면 과거 레이블과 현재 레이블의 기준이 달라진다
- 잘못 설계된 레이블은 데이터 누수(leakage) 를 유발한다 — 즉, 정답을 이미 알고 있는 정보가 입력 특성에 몰래 섞이는 것이다
6. 클래스 불균형이 심하다 (Class Imbalance)
많은 Tabular 예측 문제는 정답 분포가 극도로 불균형하다.
- 사기 거래 탐지: 전체 거래 중 사기는 0.1%에 불과하다
- 질병 진단: 희귀 질환 환자 수는 매우 적다
- 불량 제품 탐지: 불량률은 수 % 이하다
이런 상황에서 모델이 "그냥 전부 정상"이라고 예측해도 정확도가 99%가 되어버린다. 따라서 정확도(Accuracy) 외의 평가 지표가 반드시 필요하다.
여기서 클래스 불균형(Class Imbalance) 이란?
학교에서 100명 중 99명이 건강하고 1명만 아픈 상황을 생각해보자.
어떤 의사가 아무것도 검진하지 않고 모두 건강합니다 라고만 말한다면, 정확도는 무려 99%이다.
하지만 이 의사는 아무 쓸모가 없다. 정작 아픈 1명을 한 명도 못 찾아냈기 때문이다.
높은 정확도 = 좋은 모델이라는 공식은 불균형 데이터에서 완전히 무너진다.
사기 탐지, 암 진단, 불량 탐지처럼 희귀하지만 치명적인 케이스를 잡아야 하는 문제에서는 정확도 대신 다른 기준이 필요하다.
7. 도메인이 다양하고 전문 지식이 부족하다 (레퍼런스)
Tabular 데이터는 금융, 의료, 제조, 교육, 이커머스 등 어디에나 존재한다. 각 도메인마다 중요한 특성 조합(패턴)이 다르고, 그 패턴은 데이터를 분석하기 전까지 알 수 없는 경우가 많다.
정리: Tabular 데이터가 어려운 이유
| 특징 | 해결해야 할 과제 |
|---|---|
| 이질적인 특성 유형 | 서로 다른 통계적 성질 처리 |
| 공간/순서 구조 없음 | 순열 불변성 확보 |
| 소규모 데이터 | 과적합 방지, 데이터 효율성 |
| 결측값 | 불완전한 입력 처리 |
| 노이즈가 많은 레이블 | 강건성 확보, 데이터 누수 방지 |
| 클래스 불균형 | 다수 클래스 편향 방지 |
| 다양한 도메인 | 도메인 간 적응력 |
이처럼 Tabular 데이터는 결코 단순하지 않다. 오히려 이미지나 자연어처리(NLP) 분야와는 전혀 다른 고유한 어려움을 갖고 있다.
Tabular 데이터로 할 수 있는 일들
Tabular 데이터를 가지고 무엇을 할 수 있을까? 크게 다섯 가지 주요 작업이 있다.
1. 예측 (Prediction / Supervised Learning)
가장 많이 쓰이는 유형이다. 과거 데이터를 학습해서 새로운 데이터의 값을 예측한다.
- 회귀(Regression): 수치를 예측한다. 예) 집값 예측, 에너지 소비량 예측
- 분류(Classification): 카테고리를 예측한다. 예) 이탈 여부, 대출 부도 여부
예시 — 신용 점수(Credit Scoring)
대출 신청자의 연체율, 신용 한도 활용률, 대출 기간, 조회 횟수 등을 바탕으로 부도 위험도와 신용 점수를 예측한다.
2. 이상 탐지 (Anomaly Detection)
정상 패턴에서 벗어난 이상한 데이터를 찾아내는 작업이다. 보통 비지도학습 방식이며, 정상 데이터는 많지만 이상 사례는 매우 적거나 아예 레이블이 없다.
예시 — 신용카드 사기 탐지
평소 국내에서 소액 결제만 하던 카드가 갑자기 러시아에서 수백만 원짜리 전자제품 결제를 했다면? 이 거래가 이상 거래임을 자동으로 탐지한다.
3. 클러스터링 (Clustering)
레이블(정답) 없이 비슷한 데이터끼리 묶어주는 작업이다. 숨겨진 패턴이나 그룹 구조를 발견하는 데 쓰인다.
예시 — 고객 세분화(Customer Segmentation)
구매 금액, 방문 횟수, 온라인 구매 비율 등을 분석해 고객을 "전자제품 구매 고가값 온라인족", "식료품 구매 오프라인족", "명품 구매 저빈도족" 등으로 나눈다. 이후 각 그룹에 맞는 마케팅 전략을 짤 수 있다.
4. 테이블 질의응답 (Table Question Answering)
자연어로 질문을 입력하면 테이블에서 답을 찾아주는 작업이다. 자연어 이해 능력과 테이블 논리 추론 능력이 함께 필요하다.
예시 — 사내 매출 분석 어시스턴트
"아시아 지역 3분기 매출 합계가 얼마야?"라고 물으면, AI가 테이블을 조회해 "$1,800"이라고 답한다.
최근 대형 언어 모델(LLM)의 발전으로 이 작업이 크게 향상되었다.
5. 합성 데이터 생성 (Synthetic Data Generation)
원본 데이터의 통계적 특성은 그대로 유지하면서도 개인정보를 포함하지 않는 가짜 데이터를 만들어내는 작업이다.
예시 — 프라이버시 보호 의료 데이터 공유
실제 환자 데이터를 병원 외부에 제공하는 것은 법적으로 불가능하다. 하지만 원본과 통계적으로 동일한 가짜 환자 데이터를 생성한다면 연구자들이 자유롭게 활용할 수 있다.
Tabular 데이터는 우리 주변 어디에나 존재한다. 기업이 수집하는 데이터의 상당수, 그리고 그 데이터를 기반으로 내리는 의사결정의 대부분이 바로 이 행과 열의 표 형식을 띤다.
쉬워 보이지만 이질적인 특성, 결측값, 불균형, 소규모 데이터 등 독특한 어려움을 안고 있다. 이 때문에 Tabular ML은 이미지나 텍스트와는 전혀 다른 접근법이 필요하다.
2편에서는 실제로 Tabular 데이터를 가지고 머신러닝 모델을 학습시키는 전체 과정, 즉 데이터 수집부터 모델 배포까지의 파이프라인을 살펴본다. 또한 전처리 기법, 평가 지표, 그리고 모델의 예측을 해석하는 방법까지 다룬다.
'AI > ML&DL' 카테고리의 다른 글
| [ML] Tabular - 표 형식 데이터 2 (0) | 2026.06.24 |
|---|